
A discussion on how IT management technologies and methods have evolved to optimize and automate workloads to exacting performances and cost requirements.
Listen
to the podcast. Find it on iTunes. Download the transcript. Sponsor: Hewlett Packard Enterprise.
Dana Gardner: Hello,
and welcome to the next edition of the BriefingsDirect
Voice of the Innovator podcast series. I’m Dana Gardner, Principal Analyst at Interarbor Solutions, your host and
moderator for this ongoing discussion on the latest insights into hybrid IT
management.
 |
| Gardner |
IT operators have for decades been
playing catch-up to managing their systems amid successive waves of heterogeneity,
complexity, and changing deployment models. IT management technologies and
methods have evolved right along with the challenge, culminating in the capability
to optimize and automate workloads to exacting performance and cost
requirements.
Automation is about to get an AIOps
boost from new machine
learning (ML) and artificial
intelligence (AI) capabilities -- just as multicloud deployments
become more demanding.
Stay with us as we explore the
past, present, and future of IT management innovation with a 30-year veteran of
IT management, Doug de Werd,
Senior Product Manager for Infrastructure Management at Hewlett Packard Enterprise (HPE).
Welcome, Doug.
Doug de Werd: Thanks, Dana. I’m glad to be here.
Gardner: Management
in enterprise IT has for me been about taking heterogeneity and taming it, bringing
varied and dynamic systems to a place where people can operate over more, using
less. And that’s been a 30-year journey.
Yet heterogeneity these days,
Doug, includes so much more than it used to. We’re not just talking about
platforms and frameworks – we’re talking about hybrid cloud, multicloud, and
many Software as a service (SaaS) applications. It includes working securely
across organizational boundaries with partners and integrating business processes
in ways that never have happened before.
With all of that new complexity,
with an emphasis on intelligent automation, where do you see IT management going
next?
Managing management
 |
| de Werd |
de Werd: Heterogeneity
is known by another term, and that’s chaos. In trying to move from the
traditional silos and tools to more agile, flexible things, IT management is
all about your applications -- human resources and finance, for example – that run
the core of your business. There’s also software development and other internal
things. The models for those can be very different and trying to do that in a
single manner is difficult because you have widely varying endpoints.
Gardner: Sounds
like we are now about managing the management.
de Werd: Exactly.
Trying to figure out how to do that in an efficient and economically feasible
way is a big challenge.
Gardner: I
have been watching the IT management space for 20-plus years and every time you
think you get to the point where you have managed everything that needs to be managed
-- something new comes along. It’s a continuous journey and process.
But now we are bringing
intelligence and automation to the problem. Will we ever get to the point where
management becomes subsumed or invisible?
de Werd: You
can automate tasks, but you can’t automate people. And you can’t automate
internal politics and budgets and things like that. What you do is automate to provide
flexibility.
Gardner: When it
comes to IT management, you need a common framework. For HPE, HPE OneView
has been core. Where does HPE OneView go from here? How should people think
about the technology of management that also helps with those political and
economic issues?
de Werd: HPE OneView
is just an outstanding core infrastructure management solution, but it’s kind of
like a car. You can have a great engine, but you still have to have all the
other pieces.
And so part of what we are
trying to do with HPE OneView, and we have been very successful, is extending
that capability out into other tools that people use. This can be into more
traditional tools like with our Microsoft or
VMware partnerships
and exposing and bringing HPE OneView
functionality into traditional things.
The integration allows the confidence of using HPE OneView as a core engine. All those other pieces can still be customized to do what you need to do -- yet you still have that underlying core foundation of HPE OneView.
But it also has a lot to do with DevOps and the continuous integration development types of things with Docker, Chef, and Puppet -- the whole slew of at least 30 partners we have.
That integration allows the confidence
of using HPE OneView as a core engine. All those other pieces can still be
customized to do what you need to do -- yet you still have that underlying core
foundation of HPE OneView.
Gardner: And now
with HPE increasingly going to an as-a-service
orientation across many products, how does management-as-a-service work?
Creativity in the cloud
de Werd: It’s
an interesting question, because part of management in the traditional sense --
where you have a data center full of servers with fault management or break/fix
such as a hard-drive failure detection – is you want to be close, you want to
have that notification immediately.
As you start going up in the
cloud with deployments, you have connectivity issues, you have latency issues,
so it becomes a little bit trickier. When you have more up levels, up the stack,
where you have software that can be more flexible -- you can do more
coordination. Then the cloud makes a lot of sense.
 |
Management in
the cloud can mean a lot of things. If it’s the infrastructure, you tend to
want to be closer to the infrastructure, but not exclusively. So, there’s a lot
of room for creativity.
Gardner: Speaking
of creativity, how do you see people innovating both within HPE and within your
installed base of users? How do people innovate with management now that it’s
both on- and off-premises? It seems to me that there is an awful lot you could
do with management beyond red-light, green-light, and seek out those optimization
and efficiency goals. Where is the innovation happening now with IT management?
de Werd: The
foundation of it begins with automation,
because if you can automate you become repeatable, consistent, and reliable,
and those are all good in your data center.
Automation drives creativity
in a lot of different ways. You can be faster to market, have quicker releases,
those types of things. I think automation is the key.
Gardner: Any
examples? I know sometimes you can’t name customers, but can you think of
instances where people are innovating with management in ways that would
illustrate its potential?
Automation innovation
de Werd: There’s
a large biotech genome sequencing company, an IT group that is very innovative.
They can change their configuration on the fly based on what they want to do. They
can flex their capacity up and down based on a task -- how much compute and storage
they need. They have a very flexible way of doing that. They have it all automated,
all scripted. They can turn on a dime, even as a very large IT organization.
And they have had some pretty impressive ways of repurposing their IT. Today we are doing X and tonight we are doing Y. They can repurpose that literally in minutes -- versus days for traditional tasks.
Gardner: Are your
customers also innovating in ways that allow them to get a common view across
the entire lifecycle of IT? I’m thinking from requirements, through development,
deployment, test, and continuous redeployment.
de Werd: Yes,
they can string all of these processes together using different partner tools, yet
at the core they use HPE OneView and HPE Synergy
underneath the covers to provide that real, raw engine.
By using the HPE partner ecosystem integrated with HPE OneView, they have visibility. Then they can get into things like Docker Swarm. It may not be HPE OneView providing that total visibility. At the hardware level it is, but because we feed into upper-level apps they can adjust to meet the needs across the entire business process.
By using the HPE partner ecosystem integrated with HPE OneView, they have that visibility. Then they can get into things like Docker Swarm. It may not be HPE OneView providing that total visibility. At the hardware and infrastructure level it is, but because we are feeding into upper-level and broader applications, they can see what’s going on and determine how to adjust to meet the needs across the entire business process.
Gardner: In
terms of HPE
Synergy and composability, what’s the relationship
between composability and IT management? Are people making the whole
greater than the sum of the parts with those?
de Werd: They
are trying to. I think there is still a learning curve. Traditional IT has been
around a long time. It just takes a while to change the mentality, skills sets,
and internal politics. It takes a while to get to that point of saying, “Yeah, this
is a good way to go.”
But once they dip their toes
into the water and see the benefits -- the power, flexibility, and ease of it
-- they are like, “Wow, this is really good.” One step leads to the next and
pretty soon they are well on their way on their composable
journey.
Gardner: We now
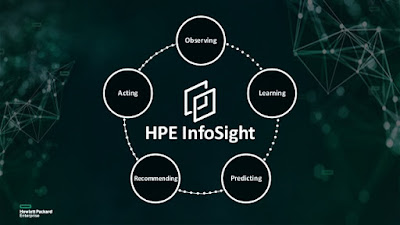
see more intelligence brought to management products. I am thinking about how HPE InfoSight is being
extended across more storage and server products.
de Werd: HPE
InfoSight is a great example. You see it being used in multiple ways, things
like taking the human element out, things like customer advisories coming out
and saying, “Such-and-such product has a problem,” and how that affects other products.
If you are sitting there looking
at 1,000 or 5,000 servers in your data center, you’re wondering how I am
affected by this? There are still a lot of manual spreadsheets out there, and
you may find yourself pouring through a list.

Today, you have the capability
of getting an [intelligent alert] that says, “These are the ones that are
affected. Here is what you should do. Do you want us to go fix it right now?” That’s
just an example of what you can do.
It makes you more efficient. You
begin to understand how you are using your resources, where your
utilization is, and how you can then optimize that. Depending on how flexible
you want to be, you can design your systems to respond to those inputs and
automatically flex [deployments] to the places that you want to be.
This leads to autonomous
computing. We are not quite there yet, but we are certainly going in that direction.
You will be able to respond to different compute, storage, and network
requirements and adjust on the fly. There will also be self-healing and self-morphing
into a continuous optimization model.
Gardner: And,
of course, that is a big challenge these days … hybrid cloud, hybrid IT, and
deploying across on-premises cloud, public cloud, and multicloud models. People
know where they want to go with that, but they don’t know how to get there.
How does modern IT management
help them achieve what you’ve described across an increasingly hybrid
environment?
Manage from the cloud down
de Werd: They
need to understand what their goals are first. Just running virtual machines (VMs)
in the cloud isn’t really where they want to be. That was the initial thing. There
are economic considerations involved in the cloud, CAPEX and OPEX arguments.
Simply moving your
infrastructure from on-premises up into the cloud isn’t going to get you where
you really need to be. You need to look at it from a cloud-native-application
perspective, where you are using micro services, containers, and cloud-enabled
programming languages -- your Javas and .NETs and all the other stateless types
of things – all of which give you new flexibility to flex performance-wise.
From the management side, you
have to look at different ways to do your development and different ways to do delivery.
That’s where the management comes in. To do DevOps and exploit the DevOps tools,
you have to flip the way you are thinking -- to go from the cloud down.
Cloud application development on-premises, that’s one of the great things about containers and cloud-native, stateless types of applications. There are no hardware dependencies, so you can develop the apps and services on-premises, and then run them in the cloud, run them on-premises, and/or use your hybrid cloud vendor’s capabilities to burst up into a cloud if you need it. That’s the joy of having those types of applications. They can run anywhere. They are not dependent on anything -- on any particular underlying operating system.
But you have to shift and get
into that development mode. And the
automation helps you get there, and then helps you respond quickly once you
do.
Gardner: Now
that hybrid
deployment continuum extends to the edge. There will be increasing data
analytics, measurement, and making deployment changes dynamically from that
analysis at the edge.
It seems to me that the way
you have designed and architected HPE IT management is ready-made for such
extensibility out to the edge. You could have systems run there that can integrate
as needed, when appropriate, with a core cloud. Tell me how management as you
have architected it over the years helps manage the edge, too.
Businesses need to move their processing further out to the edge and gain the instant response, instant gratification. You can't wait to have an input analyzed by going all the way back to the cloud. You want the processing toward the edge to get that instantaneous response.
de Werd: Businesses need to move their processing further out to the edge, and gain the instant response, instant gratification. You can’t wait to have an input analyzed on the edge, to have it go all the way back to a data source or all the way up to a cloud. You want to have the processing further and further toward the edge so you can get that instantaneous response that customers are coming to expect.
But again, being able to
automate how to do that, and having the flexibility to respond to differing workloads
and moving those toward the edge, I think, is key to getting there.
Gardner: And
Doug, for you, personally, do you have some takeaways from your years of
experience about innovation and how to make innovation a part of your daily
routine?
de Werd: One
of the big impacts on the team that I work with is in our quality assurance (QA)
testing. It’s a very complex thing to test various configurations; that’s a lot
of work. In the old days, we had to manually reconfigure things. Now, as we use
an Agile
development process, testing is a continuous part of it.
We can now respond very quickly
and keep up with the Agile process. It used to be that testing was always the
tail-end and the longest thing. Development testing took forever. Now because
we can automate that, it just makes that part of the process easier, and it has
taken a lot of stress off of the teams. We are now much quicker and nimbler in
responses, and it keeps people happy, too.
Set goals
de Werd: First,
get your house in order in terms of taking advantage of the automation available
today. Really think about how not to just use the technology as the end-state.
It’s more of a means to get to where you want to be.
Define where your organization
wants to be. Where you want to be can have a lot of different aspects; it could
be about how the culture evolves, or what you want your customers’ experience to
be. Look beyond just, “I want this or that feature.”
Then, design your full IT and development
processes. Get to that goal, rather than just saying, “Oh, I have 100 VMs running
on a server, isn’t that great?” Well, if it’s not achieving the ultimate goal
of what you want, it’s just a technology feat. Don’t use technology just for
technology’s sake. Use it to get to the larger goals, and define those goals,
and how you are going to get there.

Gardner: I’m
afraid we’ll have to leave it there. We have been exploring how IT management
technologies and methods have evolved, culminating in the ability to optimize
and automate workloads to exacting performance and cost requirements.
And we have learned that
automation is about to get an AIOps boost from new ML and AI capabilities just
as multicloud deployments become more demanding.
So please join me in thanking
our guest, Doug de Werd, Senior Product Manager for Infrastructure Management
at HPE.
And a big thank you as well to
our audience for joining us for this BriefingsDirect Voice of the Innovator interview.
I’m Dana Gardner, Principal Analyst at Interarbor Solutions, your host for this
ongoing series of Hewlett Packard Enterprise-sponsored discussions.
Thanks again for listening. Please pass this along to your IT community, and do come back next time.
Listen
to the podcast. Find it on iTunes.
Download the transcript. Sponsor: Hewlett Packard Enterprise.
A discussion on how IT management technologies and methods have
evolved to optimize and automate workloads to exacting performance and cost
requirements. Copyright Interarbor Solutions, LLC, 2005-2019. All rights
reserved.
You may also be
interested in:
- HPE and PTC Join Forces to Deliver Best Outcomes from the OT-IT Productivity Revolution
- How rapid machine learning at the racing edge accelerates Venturi Formula E Team to top-efficiency wins
- The budding storage relationship between HPE and Cohesity brings the best of startup innovation to global enterprise reach
- Industrial-strength wearables combine with collaboration cloud to bring anywhere expertise to intelligent-edge work
- HPE’s Erik Vogel on what's driving success in hybrid cloud adoption and optimization
- IT kit sustainability: A business advantage and balm for the planet
- How total deployment intelligence overcomes the growing complexity of multicloud management
- Manufacturer gains advantage by expanding IoT footprint from many machines to many insights
- How Texmark Chemicals pursues analysis-rich, IoT-pervasive path to the ‘refinery of the future’








